Every now and then, people ask me:
“I am new to agentic development, I’m building something, but I feel like I’m missing some tribal knowledge. Help me catch up!”
I’m tempted to suggest some serious stuff like multiweek courses (e.g. by HuggingFace or Berkeley), but not everyone is interested in that level of diving. So I decided to gather six simple empirical learnings that helped me a lot during app.build development.
This post is somewhat inspired by Design Decisions Behind app.build, but is generalized and aimed to be a quick guideline for newcomers in agentic engineering.
Principle 1: Invest in your system prompt
I’ve been skeptical about prompt engineering for a long time, it seemed more like shaman rituals rather than anything close to engineering. All those approaches “I will tip you $100” or “My grandmother is dying and needs this” or “Be 100% accurate or else” could be useful as local fluctuation leveraging local model inefficiency, but never worked in the longer run.
I changed my mind regarding prompt / context engineering when I realized a simple thing: modern LLMs just need direct detailed context, no tricks, but clarity and lack of contradictions. That’s it, no manipulation needed. Models are good at instruction following, and the problem is often just the ambiguous nature of the instructions.
All LLM providers have educational resources on best practices on how to prompt their models (e.g., one by Anthropic and one by Google). Just follow them and ensure your instructions are direct and detailed, no smart-pants tricks required. For example, here is a system prompt we use to make Claude generate rules for ast-grep – nothing tricky, just details on how to use the tool that the agent barely knows.
One trick we like is to bootstrap the initial system prompt with the draft created by Deep Research-like variants of LLM. It typically needs human improvements, but is a solid baseline.
Keeping a shared part of the context is beneficial for the prompt caching mechanisms. Technically, one can cache user messages too, but structuring context so that the system part is large and static and user one is small and dynamic works great.
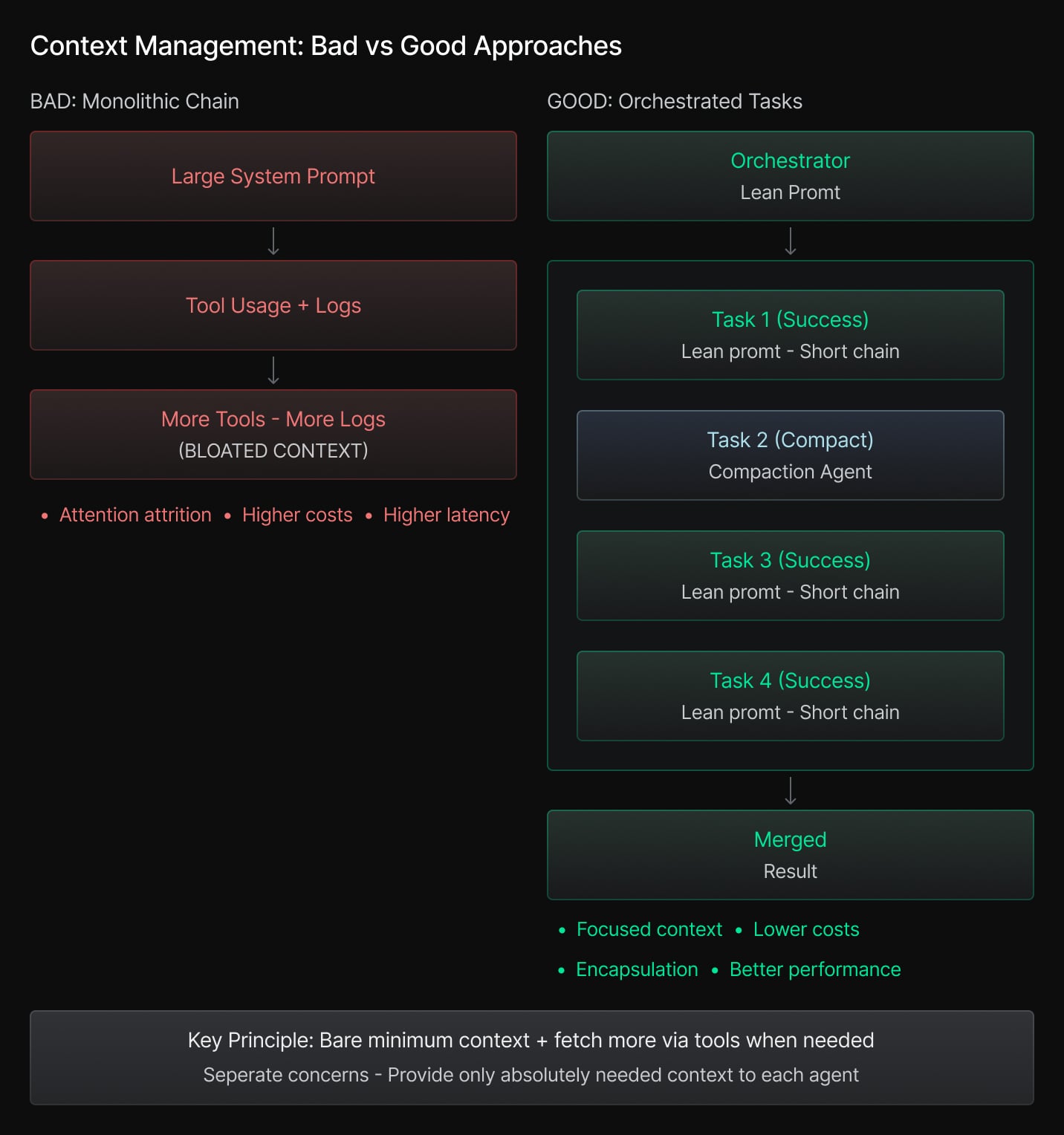
Principle 2: Split the context
Alright, a solid system prompt is here. But there is a reason why “context engineering” has been the latest trend over “prompt engineering”.
Context management is a subject for a trade-off. Without proper context, models tend to hallucinate, get off track or just refuse to provide an answer with a too large context. They’re subject to attention attrition (where models struggle to focus on relevant parts of very long contexts, leading to degraded performance on key details buried in the middle), higher costs and latency.
A principle we found useful is to provide the bare minimum of knowledge in the first place, and the option to fetch more context if needed via tools. For example, in our case it may mean listing all the project files in the prompt and providing a tool to read the files that are relevant for the requested change; although if we’re certain some file content is crucial, we can include its content in the context in advance.
Logs and other artifacts from the feedback loop can bloat the context pretty quickly.
Simple context compaction tools applied automatically can help a lot. Encapsulation was a hype word for object-oriented programming, but for context management it is even more important: separate the concerns, and provide every bit of your agentic solution only the context it absolutely needs.
Principle 3: Design tools carefully
The core feature of an AI agent is tool calling, the combination of an LLM + exposed tools + basic control flow operators makes an agent.
Designing a toolset for the agent is somewhat similar to designing an API… but actually more complex. Human API users are more capable of reading between the lines, can navigate complex docs and find workarounds. Tools created for agents are usually more limited (having too many of them is a way to pollute the context), should have direct straightforward interfaces and overall bring order to the stochastic LLM world. When building for a human user, it may be fine to design one main road and some tricks for corner cases; LLMs are very likely to misuse your loopholes, and that’s why you don’t want to have any loopholes.
Good tools typically operate on a similar level of granularity, and have a limited number of strictly typed parameters. They are focused and well-tested, like an API you’re ready to provide to a smart but distractible junior developer. Idempotency is highly recommended to avoid state management issues. Most software engineering agents have under 10 multifunctional tools (such as read_file, write_file, edit_file, execute…) with 1-3 parameters each (appbuild example, opencode example), and attaching additional tools based on context may be suitable too.
In some cases, designing an agent to write some DSL (domain-specific language) code with actions rather than calling tools one by one is a great idea. This approach was widely popularized by smolagents; however, it needs a properly designed set of functions to be exposed for the agent execution. Despite the top level structure change, the main idea remains valid: simple, sufficient but non-ambiguous and non-redundant tools are crucial for the agent performance.
Principle 4: Design a feedback loop
Good agentic solutions combine the advantages of LLMs and traditional software. One crucial way of this combination is designing a two-phase algorithm similar to the actor-critic approach: where an actor decides on actions and a critic evaluates them.
We find it useful to allow LLM Actors to be creative, and Critics to be strict. In our app generation world, it means Actors create new files or edit them, and Critics ensure this code matches our expectations. The expectations are based on handcrafted criteria: we want the code to be compilable, pass tests, type checks, linters and other validators. The Critic’s work is mostly determined, but not 100% — e.g., we can generate tests with an LLM independently and run the test suite later.
When building agents for any vertical, it is crucial to include domain-specific validation. This requires defining and checking domain invariants that must hold regardless of the agent’s specific approach — a concept ML engineers refer to as including an “inductive bias“.
Software engineering is an industry most affected by AI agents for precisely this reason. The feedback loop is incredibly effective: it is easy to filter out bad results using very straightforward validators such as compilers, linters, and tests. This affects performance on two levels: foundational models are trained on such verifiable rewards at scale, and later product engineers can leverage these learned properties.
This same thinking applies to other domains. As an example, if a travel-oriented agent suggests a multi-leg flight, the first thing is to verify those connections exist. Likewise, if a bookkeeping agent’s result does not satisfy double-entry principles, it is a bad result and it should not be accepted.Feedback loops are tightly coupled with the concept of “guardrails” available in many frameworks. Agents are moderately good at recovering. Sometimes, a bad result is worth trying to fix (sending a next message to the LLM reflecting “hey, your previous solution is not acceptable because of X”), other times a chain of bad fixes is not fixable anymore – just discard and try again.
Agentic system should be ready for both hard and soft failures with different recovery strategies, and those recovery strategies together with the guardrails are the essence of a feedback loop. You can think of it in a manner similar to the Monte-Carlo tree search concept: some branches are promising and should be developed further, some are dead-end and should be cut away.
Principle 5: LLM-driven error analysis
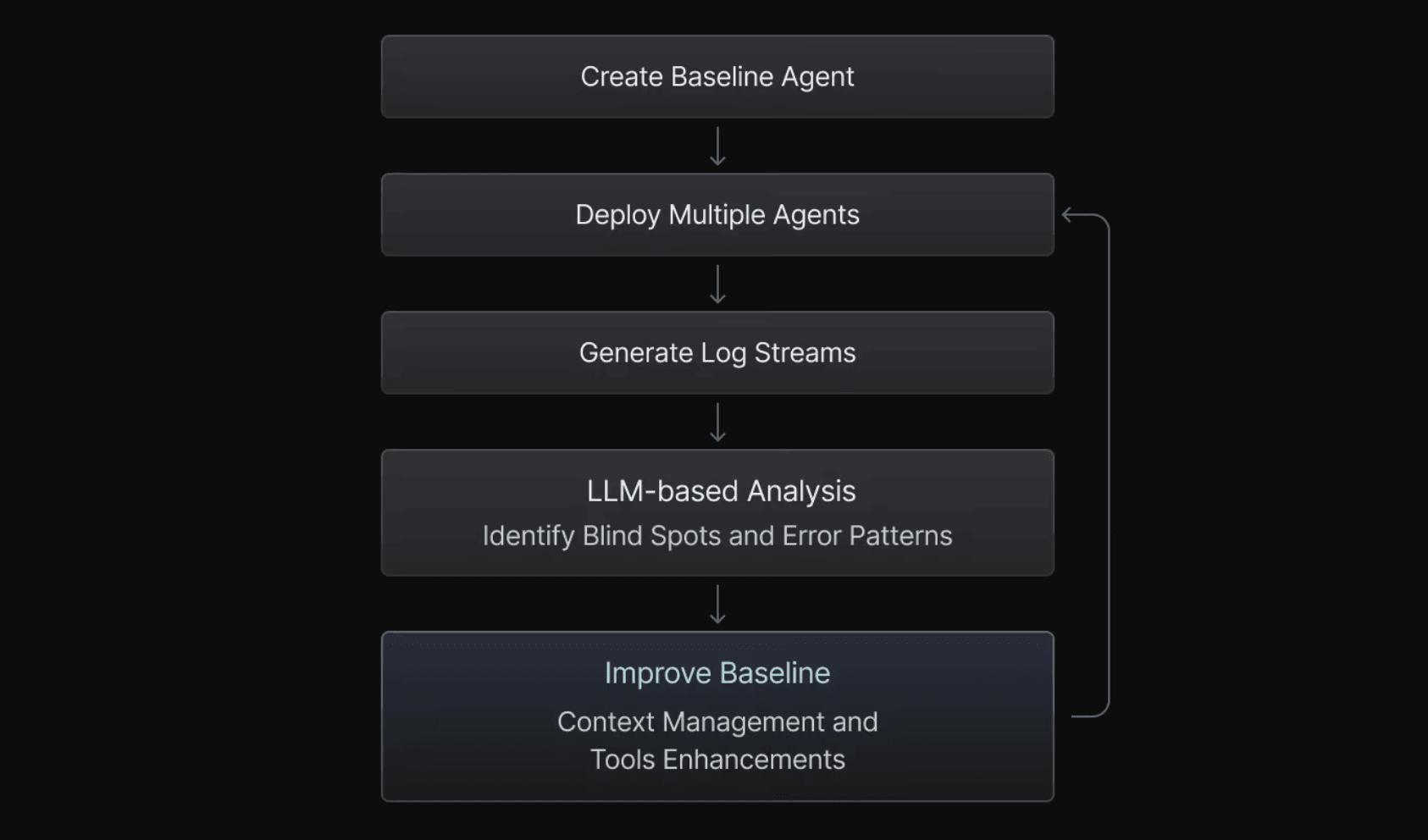
Once you have a basic agent and a feedback loop attached, you can iterate and improve. Error analysis has always been a cornerstone in AI/ML engineering, and AI agents are not any different. One approach to error analysis is to review common failures, but agents are so productive! It is often easy to spawn dozens of agents, keep them running on different tasks, generate tons of logs (hope your feedback loop has some observability feature built in, right?). No matter how productive you are, it is very likely that agents’ log stream won’t be readable.
That is why a simple meta-agentic loop is very powerful:
- Make a baseline
- Get some trajectories / logs
- Analyze them with a LLM (kudos to Gemini’s 1M context)
- Improve the baseline based on the received insights.
Very often this will reveal blind spots in the context management or tools provided.
Principle 6: Frustrating behavior signals system issues
LLMs are powerful these days, and that is why people are getting frustrated fairly quickly when agents do really stupid things, or completely ignore the instructions. The reality is that instruction-tuned models are also very prone to reward hacking, meaning they’re doing whatever possible to satisfy the goal as it is interpreted. This is, however, not necessarily the goal the original system designer had in mind.
The insight is: an irritating issue can be caused not by the LLM flaws, but a system error such as the lack of the tool to handle required to solve the problem or ambiguous paragraph in the system prompt. Recently, I was cursing loudly: why on Earth does the agent not use the integration provided to get the data and use the simulated random data instead despite my explicit request not to do it?
I read the logs and realized I am the silly one here – I didn’t provide the agent with proper API keys, so it tried to fetch the data, failed multiple times in a row in the same way and went for a workaround instead. That was not the only accident: for example, we also observed similar behavior with agents trying to write a file while missing file system access.
Conclusion
Building effective AI agents isn’t about finding a silver bullet of a great prompt or an advanced framework — it is system design and proper software engineering. Focus on clear instructions, lean context management, robust tool interfaces, and automated validation loops. When your agent frustrates you, debug the system first: missing tools, unclear prompts, or insufficient context are usually the culprits, not model limitations.
Most importantly, treat error analysis as a first-class citizen in your development process. Let LLMs help you understand where your agents fail, then systematically address those failure modes. The goal isn’t perfect agents — it’s reliable, recoverable ones that fail gracefully and can be improved iteratively.
This blog post was originally published in the app.build blog.